

We are extremely excited to announce Avail — an important component of a completely new way on how future blockchains will work. Avail is a general-purpose, scalable data availability-focused blockchain targeted for standalone chains, sidechains, and off-chain scaling solutions.
Avail provides a robust data availability layer by using an extremely secure mathematical primitive — data availability checks using erasure codes with a key innovation — we use Kate polynomial commitments to create a 2D data availability scheme that avoids fraud proofs, does not require honest majority assumptions, and has no reliance on honest full node peer to gain confidence that the data is available.
Avail provides a common data availability layer that can be used by varying execution environments such as standalone chains, sidechains, and off-chain scaling solutions. In the long term, it will enable a wide variety of experimentation on the execution environment side and eventual implementation, without teams and projects having to bootstrap their own security. Chains created using Polygon SDK, Cosmos SDK or Substrate can benefit from using Avail for this purpose.
Avail decouples the transaction execution and validity from the consensus layer so that the consensus is only responsible for a) ordering transactions and b) guaranteeing their data availability.
Key objectives
Enable standalone chains or sidechains with arbitrary execution environments to bootstrap validator security without needing to create and manage their own validator set by guaranteeing transaction data availability
Layer-2 solutions such as Validiums to offer increased scalability throughput by using Avail as an off-chain data availability layer
We have been working on Avail in stealth since the end of 2020 and currently, it is at the Devnet stage. A testnet is in the works. More details about the problem, architecture, and solution including references to the codebase can be found in the reference document. For more information regarding Avail, please join our Discord server or email us at [email protected].
Background
In present-day Ethereum-like ecosystems, there are mainly three types of peers:
Validator nodes
Full nodes
Light clients
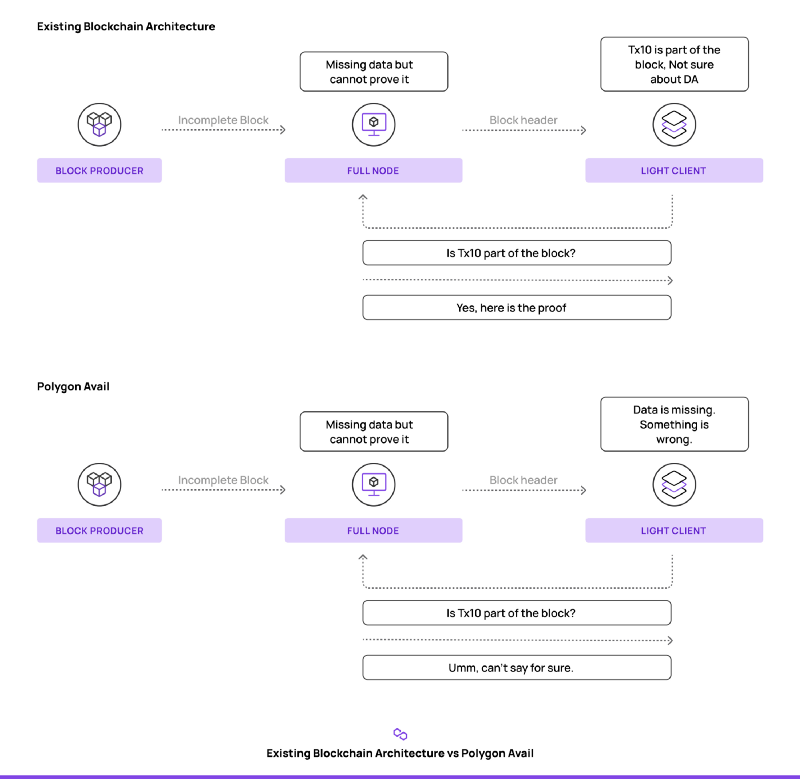
A block is appended to the blockchain by a validator node that collects transactions from the mempool, executes them, generates the block before propagating it across the network. The block contains a small block header containing digest and metadata related to the transactions included in the block. The full nodes across the network receive this block and verify its correctness by re-executing the transactions included in the block. The light clients only fetch the block header and fetch transaction details from neighboring full nodes on an as-needed basis. The metadata inside the block header enables the light client to verify the authenticity of the received transactional details.
While this architecture is extremely secure and has been widely adopted, it has some serious practical limitations. Since light clients do not download the entire block, they can be tricked into accepting blocks whose underlying data is not available. The block producer might include a malicious transaction in a block and not reveal its entire content to the network. This is known as the data availability problem and poses serious threats to light clients. What makes it worse is that data unavailability is an unattributable fault, which prohibits us from adding a fraud proof construction that allows the full nodes from informing the light clients about missing data in a convincing manner.
Existing Blockchain Architecture vs Polygon Avail
In contrast, Avail solves this problem by taking a different approach — instead of verifying the application state, it concentrates on ensuring the availability of the transaction data posted and also ensures transaction ordering. A block that has consensus is considered valid only if the data behind that block is available. This is to prevent block producers from releasing block headers without releasing the data behind them, which would prevent clients from reading the transactions necessary to compute the state of their applications.
Avail reduces the problem of block verification to data availability verification, which can be done efficiently with constant cost using data availability checks. Data availability checks utilize erasure codes, which are used heavily in data redundancy design.
Data availability checks require each light client to sample a very small number of random chunks from each block in the chain. A set of light clients can collectively sample the entire blockchain in this manner. A good mental model for this is systems like p2p file sharing systems such as Torrent, where different seeds and peers typically store only some parts of a file.
Note these techniques are going to be heavily used in systems such as Ethereum 2.0 and Celestia (formerly LazyLedger) among others.
This leads to an interesting consequence as well: the more non-consensus nodes that are present in the network, the greater the block size (and thus throughput) you can have securely. This is a useful property, as it means non-consensus nodes can also contribute to the throughput and security of the network.
KZG commitment based scheme
In the KZG commitment based scheme that Avail uses, there are three main features:
Data redundancy so that it is hard for the block producer to hide any part of the block.
Fraud proof free guarantee of correct erasure coding
Vector commitments that allow full nodes to convince transaction inclusion to light nodes using succinct proof.
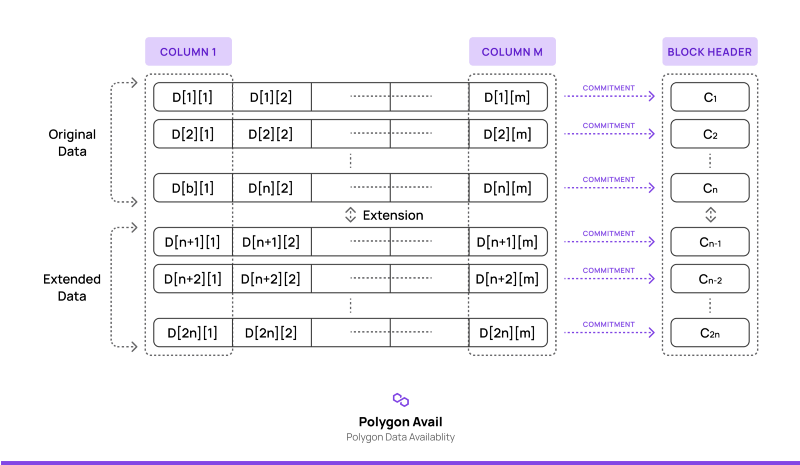
In simple terms, the entire data in a block is arranged as a two-dimensional matrix. The data redundancy is brought in by erasure coding each column of the matrix to double the size of the original one. Kate commitments are used to commit to each of the rows and the commitment is included in the block header. The scheme makes it easy to catch a data hiding attempt as any light client with access to only block headers can query random cells of the matrix and get short proofs (thanks to the Kate commitments) that can be checked against the block headers. The data redundancy forces the block producer to hide a large part of the block even if it wants to hide just a single transaction, making it susceptible to getting caught on random sampling. We avoid the need for fraud proofs as the binding nature of the Kate commitments makes it very computationally infeasible for block producers to construct wrong commitments and not get caught. Furthermore, the commitments for the extended rows can be computed using the homomorphic property of the KZG commitment scheme.
The KZG commitment scheme
Even though we mention the main features of the construction here, there are others like partial data fetches and collaborative availability guarantees. We omit the details here and would revisit them in a follow-up article.
Now might be a good time to take an example and walk through a real-world use case. Suppose a new application wants to host an application-specific standalone chain. It spins up a new PoS chain using Polygon SDK or any other similar framework like Cosmos SDK or Substrate and embeds the business logic inside it. But it faces the bootstrapping problem of gaining enough security through validator staking.
To avoid that, it uses Avail for transaction ordering and data availability. Application users submit transactions to the Polygon SDK chain, which are forwarded automatically to Avail, and order is maintained there itself. The ordered transactions are picked up by an operator (or multiple operators) and the final application state is constructed according to the business logic. The application users are assured that the ordered data is available and can themselves reconstruct the application state at any point they wish, enabling them to use the chain with a strong guarantee of security provided by Avail.
Although the above example talks about a new standalone chain using Avail for security, the platform is generic and any existing chain can also use it for ensuring data availability. In the next section, we briefly mention how Avail can help existing rollups in scaling Ethereum.
A note on data availability for off-chain scaling solutions on Ethereum
A wide variety of Ethereum Layer 2 solutions such as optimistic rollups, ZK rollups, and Validiums have been proposed. These solutions move execution off-chain while ensuring application verification and data availability on-chain. While the off-chain execution-based architecture improves throughput, it is still limited by the amount of data that the main chain like Ethereum can handle. This is because although the execution is off-chain, the verification or dispute resolution is strictly on-chain. The transactional data is submitted as calldata on Ethereum to ensure that the data is available for future reconstruction. This is extremely important.
In the case of optimistic rollups, the operator may submit invalid transactions and then suppress parts of the block to the world. This way, the other full nodes in the system will not be able to verify whether the submitted assertion is correct. Due to lack of data, they will not be able to produce any fraud-proof/challenge to show that the assertion is indeed invalid.
In the case of Zero-knowledge based roll-ups, the ZKP soundness ensures that accepted transactions are valid. However, even in the presence of such guarantees, not revealing the data backing a transaction can have serious side effects. It may lead to other validators not being able to calculate the current state of the system, as well as a user being excluded from the system and their balance frozen as they do not have the information (witnesses) required to access that balance.
We recognize that to achieve higher throughput, we not only need to put execution off-chain but also need to have a scalable data hosting layer that guarantees data availability.
This blockchain design needs to address the following components:
Data Hosting and Ordering: This component would receive transactional data and order it without any execution. It would then store the data and ensure complete data availability in a decentralized manner. This is the crux of Avail.
Execution: The execution component should take ordered transactions from Avail and execute them. It should create a checkpoint/assertion/proof and submit it to the data verification layer. We call this the execution layer.
Verification/Dispute Resolution: This component represents the main chain to which the system is anchored. The security of the design is dependent on the robustness and security properties of this component. The checkpoints/assertion/proof submitted by the execution layer is processed by this layer to guarantee that only valid state transitions are accepted in the system (provided that the data is available). We refer to this component as the data verification layer.
Avail provides this robust data hosting and ordering component. We envision multiple off-chain scaling solutions or legacy execution layers to form the execution layer. We are working on the tooling required to make this possible using Avail and will share more on this in the coming future. For more information regarding Avail, please join our Discord server or email us at [email protected].
Source : blog.polygon